During my interview with Gene Kim on for Functional Geekery, Episode 128, Gene talked about how he had a problem he was asking different people for how they would solve it nicely with a functional approach, to see how to improve his Clojure solution to be more idiomatic.
His problem was on “rewriting” Ibid. entries in citation references, to get the authors names instead of the Ibid. value, as Ibid. is a shorthand that stands for “the authors listed in the entry before this”.
As he was describing this problem, I was picturing the general pseudo-code with a pattern match in my head. To be fair, this has come from a number of years of getting used to thinking in a functional style as well as thinking in a pattern matching style.
The following Erlang code is a close representation to the pseudo-code that was in my head.
-module(ibid).
-export([ibid/1]).
ibid(Authors) ->
ibid(Authors, []).
ibid([], UpdatedAuthors) ->
{ok, lists:reverse(UpdatedAuthors)};
ibid(["Ibid." | _], []) ->
{error, "No Previous Author for 'Ibid.' citation"};
ibid(["Ibid." | T], UpdatedAuthors=[H | _]) ->
ibid(T, [H | UpdatedAuthors]);
ibid([H | T], UpdatedAuthors) ->
ibid(T, [H | UpdatedAuthors]).
Running this in the Erlang shell using erl results in the following
> ibid:ibid(["Mike Nygard", "Gene Kim", "Ibid.", "Ibid.", "Nicole Forsgren", "Ibid.", "Jez Humble", "Gene Kim", "Ibid."]).
{ok,["Mike Nygard","Gene Kim","Gene Kim","Gene Kim",
"Nicole Forsgren","Nicole Forsgren","Jez Humble","Gene Kim",
"Gene Kim"]}
> ibid:ibid(["Ibid."]).
{error,"No Previous Author for 'Ibid.' citation"}
Throughout the editing of the podcast, I continued to think about his problem, and how I would approach it in Clojure without built-in pattern matching, and came up with the following using a cond instead of a pure pattern matching solution:
(defn
update_ibids
([authors] (update_ibids authors []))
([[citation_author & rest_authors :as original_authors] [last_author & _ :as new_authors]]
(let [ibid? (fn [author] (= "Ibid." author))]
(cond
(empty? original_authors) (reverse new_authors)
(and (ibid? citation_author) (not last_author))
(throw (Exception. "Found `Ibid.` with no previous author"))
:else (recur
rest_authors
(cons
(if (ibid? citation_author)
last_author
citation_author)
new_authors))))))
And if we run this in the Clojure REPL we get the following:
user=> (def references ["Gene Kim", "Jez Humble", "Ibid.", "Gene Kim", "Ibid.", "Ibid.", "Nicole Forsgren", "Micheal Nygard", "Ibid."])
user=> (update_ibids [])
()
user=> (update_ibids ["Ibid."])
Execution error at user/update-ibids (REPL:8).
Found `Ibid.` with no previous author
user=> (update_ibids references)
("Gene Kim" "Jez Humble" "Jez Humble" "Gene Kim" "Gene Kim" "Gene Kim" "Nicole Forsgren" "Micheal Nygard" "Micheal Nygard")
That solution didn’t sit well with me (and if there is a more idiomatic way to write it I would love some of your solutions as well), and because of that, I wanted to see what could be done using the core.match library, which moves towards the psuedo-code I was picturing.
(ns ibid
(:require [clojure.core.match :refer [match]]))
(defn
update_ibids
([authors] (update_ibids authors []))
([orig updated]
(match [orig updated]
[[] new_authors] (reverse new_authors)
[["Ibid." & _] []] (throw (Exception. "Found `Ibid.` with no previous author"))
[["Ibid." & r] ([last_author & _] :seq) :as new_authors] (recur r (cons last_author new_authors))
[[author & r] new_authors] (recur r (cons author new_authors)) )))
And if you are trying this yourself, don’t forget to add to your deps.edn file:
{:deps
{org.clojure/core.match {:mvn/version "0.3.0"}}
After the first couple of itches were scratched, Gene shared on Twitter Stephen Mcgill’s solution and his solution inspired by Stephen’s.
https://twitter.com/RealGeneKim/status/1201922587346866176
(Edit 2022-05-02 : I took out the Twitter embed and changed the embed to be an HTML link to Twitter if you are interested in seeing the post as it was pointed out that tracking cookies were being dropped by Twitter, in an effort to reduce cookies being dropped by this site.)
And then, just for fun (or “just for defun” if you prefer the pun intended version), I did a version in LFE (Lisp Flavored Erlang) due to it being a Lisp with built in pattern matching from being on the Erlang runtime.
(defmodule ibid
(export (ibid 1)))
(defun ibid [authors]
(ibid authors '[]))
(defun ibid
([[] updated]
(tuple 'ok (: lists reverse updated)))
(((cons "Ibid." _) '[])
(tuple 'error "No Previous Author for 'Ibid.' citation"))
([(cons "Ibid." authors) (= (cons h _) updated)]
(ibid authors (cons h updated)))
([(cons h rest) updated]
(ibid rest (cons h updated))))
Which if we call it in LFE’s REPL gives us the following:
lfe> (: ibid ibid '["Mike Nygard" "Gene Kim" "Ibid." "Ibid." "Nicole Forsgren" "Ibid." "Jez Humble" "Gene Kim" "Ibid."])
#(ok
("Mike Nygard"
"Gene Kim"
"Gene Kim"
"Gene Kim"
"Nicole Forsgren"
"Nicole Forsgren"
"Jez Humble"
"Gene Kim"
"Gene Kim"))
lfe> (: ibid ibid '["Ibid."])
#(error "No Previous Author for 'Ibid.' citation")
If you have different solutions shoot them my way as I would love to see them, and if there looks to be interest, and some responses, I can create a catalog of different solutions similar to what Eric Normand does on his weekly challenges with his PurelyFunctional.tv Newsletter.

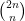 is the solution to the number of paths through the square the function
is the solution to the number of paths through the square the function